Abstract
Blind image inpainting aims at recovering the content from a corrupted image in which the mask indicating the corrupted regions is not available in inference time. Inspired that most existing methods for inpainting suffer from complex contamination, we propose a model that explicitly predicts the real-valued alpha mask and contaminant to eliminate the contamination from the corrupted image, thus improving the inpainting performance. To enhance the overall semantic consistency, the attention mechanism of transformers is exploited and integrated into our inpainting network. We conduct extensive experiments to verify our method against blind and non-blind inpainting models and demonstrate its effectiveness and generalizability to different sources of contaminant.
Method
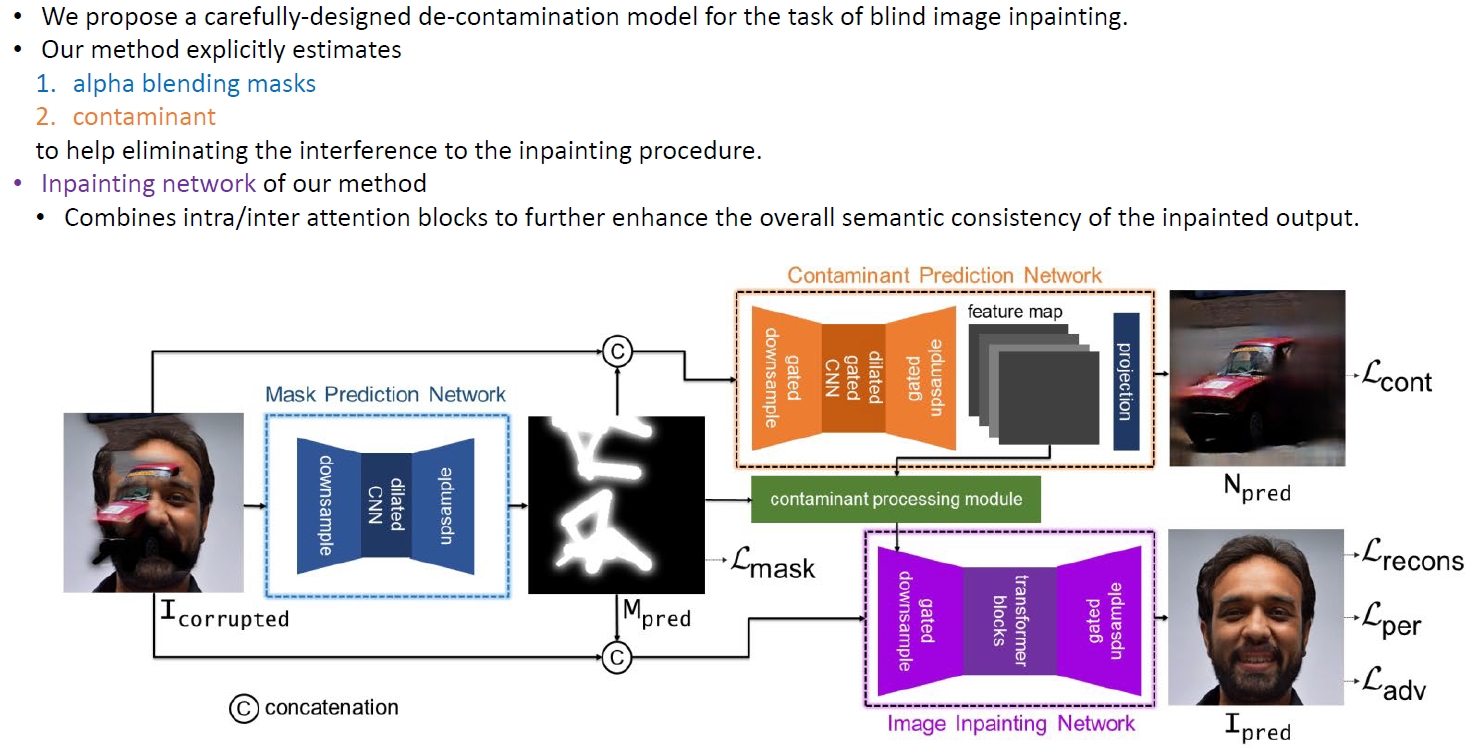
Result
Examples of qualitative results ↓

Example results of the generalizability test ↓

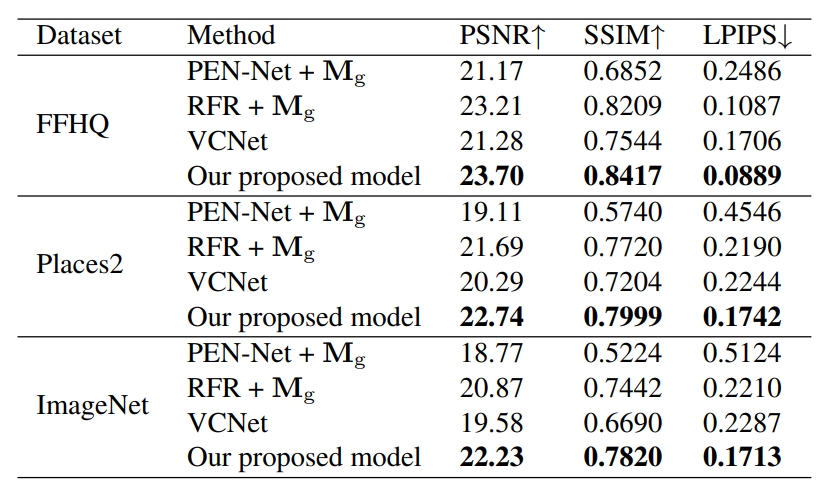
Quantitative comparison ↓
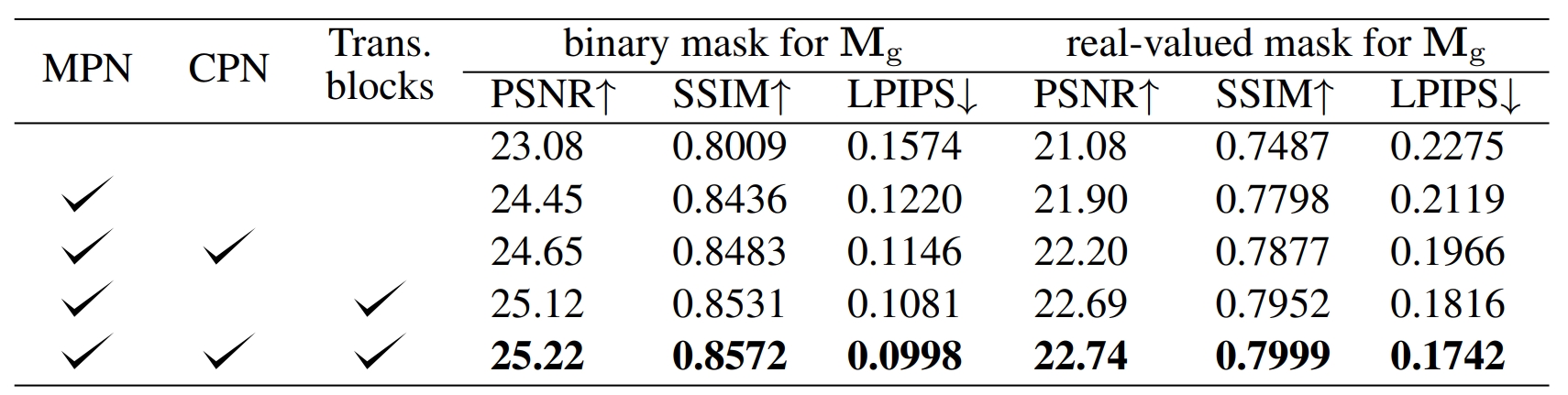
Ablation study
Citation
@inproceedings{li2023icassp,
title = {Decontamination Transformer for Blind Image Inpainting},
author = {Chun-Yi Li and Yen-Yu Lin and Wei-Chen Chiu},
booktitle = {IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP)},
year = {2023}
}